Stability AI has recently launched "Stable Audio," a pioneering latent diffusion model that's set to transform audio generation. This innovation represents a significant advance for generative AI, merging text metadata with audio duration and start time conditioning to provide unparalleled control over the creation of audio content, including full-length songs.
Historically, audio diffusion models struggled with the constraint of generating audio of fixed durations, often resulting in incomplete musical segments. This issue stemmed from the models being trained on arbitrary audio chunks cropped from extensive files and set into rigid lengths. Stable Audio overcomes this challenge by allowing the generation of audio with specified lengths, adhering to the training window size.
One of the remarkable features of Stable Audio is its capability to deliver faster inference times by utilizing a heavily downsampled latent representation of audio. This approach significantly improves over previous models by using cutting-edge diffusion sampling techniques. The flagship model can generate 95 seconds of stereo audio at a 44.1 kHz sample rate in less than a second when powered by an NVIDIA A100 GPU.
A Sound Foundation
The core architecture of Stable Audio includes a variational autoencoder (VAE), a text encoder, and a U-Net-based conditioned diffusion model. The VAE compresses stereo audio into a lossy latent encoding that resists noise, which accelerates both the generation and training processes. This design draws on the Descript Audio Codec encoder and decoder architectures, ensuring high-quality output while supporting encoding and decoding for audio of varying lengths.
To leverage text prompts, Stability AI employs a text encoder based on a CLAP model trained on their dataset. This allows the model to imbue text features with insights about word-sound relationships. These text features, extracted from the CLAP text encoder's penultimate layer, integrate into the diffusion U-Net via cross-attention layers.
During training, the model learns to incorporate two primary properties from audio segments: the start time ("seconds_start") and the total audio file duration ("seconds_total"). These properties transform into discrete learned embeddings per second, concatenated with text prompt tokens. Such conditioning empowers users to specify desired audio lengths during inference.
The diffusion model powering Stable Audio boasts an impressive 907 million parameters and employs a nuanced combination of residual, self-attention, and cross-attention layers to denoise inputs while considering text and timing embeddings. To optimize for memory efficiency and scalability with longer sequences, the model integrates memory-efficient attention implementations.
The flagship model trains on an extensive dataset of over 800,000 audio files, featuring music, sound effects, and single-instrument stems—a colossal 19,500 hours of audio compiled in collaboration with AudioSparx, a leading stock music provider. Stable Audio marks the forefront of audio generation research emanating from Stability AI’s lab, Harmonai, focusing on enhancing model architectures, datasets, and training methodologies to elevate output quality, controllability, and inference speed.
Stability AI alludes to forthcoming releases from Harmonai, suggesting open-source models based on Stable Audio and accessible training code could be on the horizon. This latest accomplishment adds to a streak of achievements by Stability, which earlier this week joined seven other top AI firms in signing the White House’s voluntary AI safety pledge.
Discover the potential of Stable Audio for yourself here.
As we delve deeper into the transformative capabilities of AI in audio generation, the potential applications across various creative domains continue to unfold, bridging the gap between technology and human creativity. This progress not only reshapes how we perceive audio content creation but also paves the way for innovations in visual storytelling and video content, where similar advancements are unleashing new possibilities.
The Future of AI in Video Content Creation
In our digital era, video stands as the dominant medium for storytelling. Whether you're a brand strategist, content creator, or someone who loves sharing moments visually, producing high-quality videos is essential for capturing and retaining attention. Yet, traditional video production often demands significant time, money, and specialized skills.
This is where AI makes a compelling entrance.
Dreamlux provide AI video generator tools that automate everything from animations and voiceovers to seamless scene transitions, democratizing video creation for all.
As AI continues to push creative boundaries, it’s also opening doors for heartwarming, imaginative storytelling featuring our furry companions.
Enter the World of AI Pet Lover Generator
The AI Pet Lover Generator is a delightful new effect that transforms ordinary pet photos into charming, anthropomorphic video scenes. Based on your uploaded image, the AI animates two adorable pets standing upright on hind legs, with their front limbs gently embracing or leaning against each other like human arms.
Outfitted in matching couple-style clothing, the pets appear to interact affectionately, facing the camera and creating a warm, whimsical moment that feels both playful and emotional. Whether you’re a pet parent, an artist, or a creator looking to craft something truly unique, this tool adds a magical human-like touch to your pets in a few simple steps.
With AI bringing both character and connection to life, even animals can become the stars of deeply expressive visual stories.
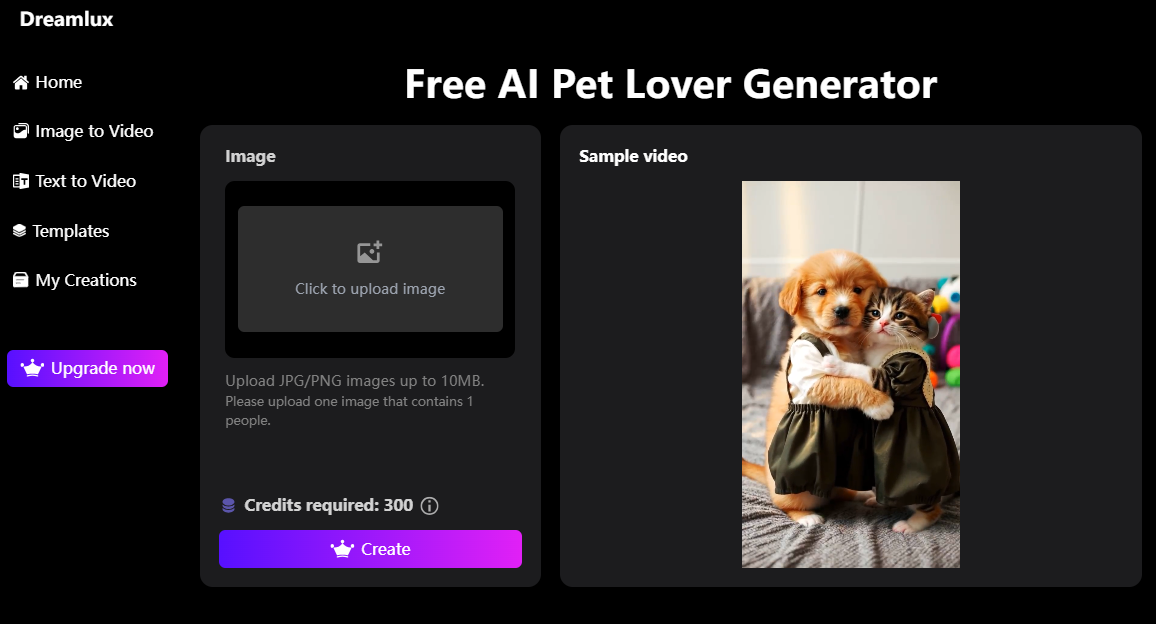
How to Use Dreamlux AI Pet Lover Generator for a Heartwarming Pet Scene
Follow the steps below to create a lovable pet couple animation with Dreamlux.ai:
- Go to the official Dreamlux website: https://dreamlux.ai and click on "Templates"
- Select the "Free AI Pet Lover Generator" from the template list
- Upload a photo featuring two pets you’d like to animate
- Click "Create", and let the AI Pet Lover Generator transform them dynamically in just minutes
Dreamlux helps you turn your pets into expressive, lovable characters.






